First off, props to tester superstar and my colleague
Ann Flismark who just gave a talk at SAST on the implementation of session-based test management together with
James Bach and Michael Albrect of
AddQ. If you happened to listen to them and found it interesting, you can read more about the everyday practicalities below (the tool we use, for example).
Current focus: metrics. There's a lot of talk in the test organization on KPIs and comparisons. Having recently moved from script-based to exploratory testing, we face a problem of bringing our old metrics to our current way of working.
By "old metrics" I mean things like
- number of testcases per requirement (planned/passed/failed)
- number of automated test cases vs number of manual test cases
and so on.
Are these metrics interesting? There is no easy answer. On one hand, counting the number of executed test cases is meaningless since a test case is not really a measure of anything. On the other hand, these numbers are deeply rooted in all levels of the organization and should be treated with a certain amount of respect.
Also, it is not uncommon for my client to be involved in project with other companies and external stakeholders. They often approach the test organization with questions like "how many test cases have you planned for this feature?" or "what is the pass rate of tests for feature so-and-so?". One way would be to slap everyone around with the hard truth that we no longer count test cases, since we have none. That also means, however, that we need to educate everyone in our way of working (which, of course, is the long-term solution). Another, more instant, approach would be to provide other, comparable, metrics. Is this something we can do? Yes and no.
The fundamental requirement on us testers has been worded as "you need to provide metrics". Having pondered this request long and hard, as well as googling for "metrics in exploratory testing", "session based test management metrics", etc (and not finding much, I might add), we have arrived at a couple of conclusions.
Primo, we collect metrics that are valuable to us and that we can
1. use to better ourselves and increase our efficiency
2. show our stakeholders once they are up-to-speed on what session-based test management is all about
These include things as time spent in session, time spent setting up test environments (and other tasks), and how these evolve over time.
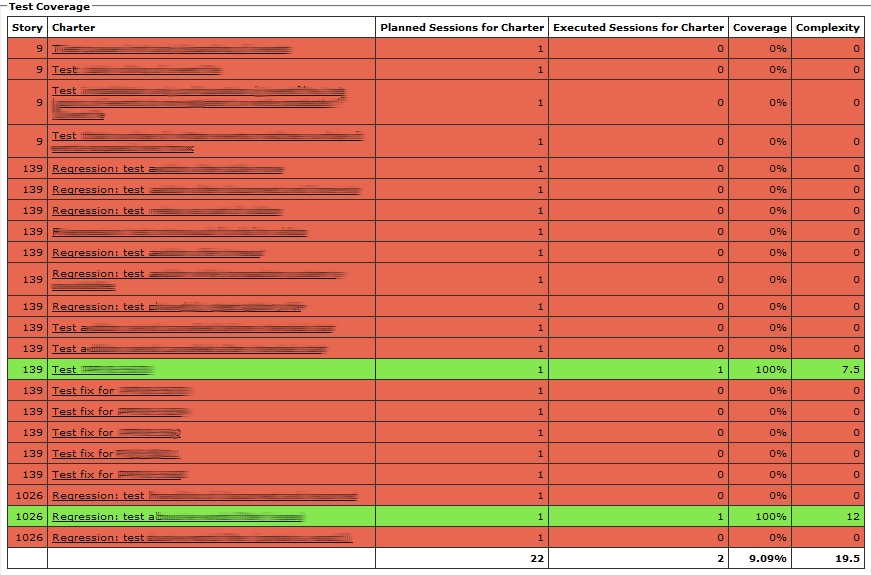
Secondo, we collect and compile metrics that can be translated to and compared with traditional figures. These include, for example, requirement coverage, test coverage and test session complexity.
The thought process behind producing and displaying metrics has led to a somewhat more rigid and refined test management process - something we constantly strive for.
The Process - Improved
Each sprint starts with a day of planning where we decide to gnaw our way through a number of stories. Each story exists as a high-level requirement written by a project manager and is labeled with a number.
During the test planning, I, as a tester, go through the stories and for each
1 draw a sketch of the use cases, components involved, how it ties to the rest of the system, etc, on a whiteboard
2 get the developer (and, possibly, project manager) to detail the sketch with me, point out things I may have missed, and give input on risk areas and what to focus on while testing
3 cover the sketch with post-its, each holding a charter of 1-2 sentences e.g. "test the write-to-file throttling functionality" or "regression: test the auditing of this-and-this data to backend"
4 estimate the number of sessions I will need to cover each of the charters
I then update the relevant playbook accordingly, and bring the charters into my nifty tool - a simple text file will hold my test plan:
story;charter;no of planned sessions
9;test the write-to-file throttling functionality;1
and so forth - one line per planned charter.
When I'm ready to do a session, I visit the tool and am instantly presented with the current test coverage. I pick a charter that is planned but untested (or not tested enough), and get to work (simply clicking it will give me a session report template with the basics already filled out). As I check my reports into our version control system, the test status is updated automatically.
The tool then shows me
- what stories we cover in the sprint
- what stories I have adressed by planning tests (writing charters) for them
- what charters I have planned for each story
- how many sessions I have planned for each charter
- how many sessions I have planned for each story
- what charters I have covered with sessions
- test work left for this sprint
And, of course, the good ol' stuff like
- how much time I have spent in session (and on various other tasks of my choice)
- how that time has evolved over time
- how many sessions I have spent testing a certain component or functional area
And another thing, which is something of an experiment at this stage .. session complexity. The thoughts behind it were something like
"the session report contains the steps I took during the session, such as
- went through use-case UC12 with user account F18, verified audited data in table T_11K
... couldn't each such step be translated to a scripted test case? At least the headline of a scripted test case, so we can count them ...".
So now we count them. Is that good? I'm not sure. But it's comparable. If someone asks me "how many test cases have you run for feature so-and-so?" I could say "17" if I don't feel like giving the whole here's-how-exploratory-testing-works-lecture. If that number is meaningful to them, why not? I believe in taking small steps, and making sure everyone understands why something is the way it is.
So what about failed test cases? Well, we traditionally counted passed/failed test cases based on the test run during the end of our sprint. Every failed test case would result in a bug report. If that bug was serious enough it would get fixed, we would run the test case again and set it to passed. If it wasn't a showstopper, the bug report would stay open after the end of the sprint. Short-cutting that whole process, we could translate "failed test cases" to "open bug reports after end of sprint".
As always, this is in an experimental stage. We hope to be on the right path. Do you spot anything missing? Are we ignoring important metrics or measuring wrong? How do you do it?
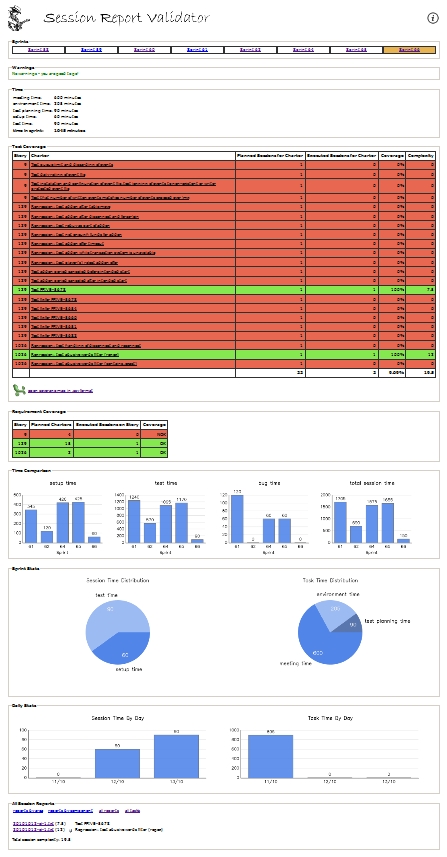
Just because I like visualizing, here's a bird's eye view of my SBTM tool in its entirety:
... with links to previous sprints on top, followed by a summary of all the time entries I have written (setup time, test time, etc). We talked about the big red-and-green graph earlier, and the little one just below shows requirement coverage (what stories have we planned for, and whether they are adressed by planned test charters). The blue graphs show trends for certain time entries (setup time and test time being the most interesting), how the time spent is distributed among tasks and by day over the sprint. At the bottom are links to all session reports, sortable by date, covered component or area.